
Een hackathon met een klant heeft it-dienstverlener CGI een tool opgeleverd die het zoekproces in grote en verscheidene databronnen automatiseert, en door een koppeling met een llm (groot taalmodel) de antwoorden personaliseert. CGI noemt het een chatbot en volgens Koen van Kan, ai-consultant bij CGI, zijn er veel gebruiksmogelijkheden.
Het idee om hieraan te werken, legt Van Kan uit, is ontstaan door de beperking die ChatGPT heeft, namelijk een kennisachterstand. ChatGPT is gevoed met gegevens die niet verder teruggaan dan 2021. De samenvoeging van het redeneervermogen van llm’s met aangepaste gegevens zou een krachtig hulpmiddel kunnen zijn. Dit is wat het conversational artificial intelligence team van CGI – gevestigd in Amsterdam – wilde onderzoeken.
‘Hoe groter de kennisbank, bijvoorbeeld een intranet, waarbinnen iemand een antwoord zoekt, hoe langer het duurt voordat je een antwoord krijgt’, ziet Van Kan in de praktijk. Uiteindelijk heeft CGI een drietrapsraket gebouwd. Dit begint met de samenstelling van een actuele en volledige kennisbank. De tweede fase is semantisch zoeken, gevolgd door een prompt engineered antwoord.
Prompt engineering is een techniek die wordt gebruikt in natuurlijke taalverwerking (nlp) om tekst te genereren die lijkt op door mensen geschreven tekst. Hierbij wordt een machine-learningmodel getraind op grote hoeveelheden tekstgegevens om het volgende woord in een zin te voorspellen. Het model kan dan worden gebruikt om nieuwe tekst te genereren door het meest waarschijnlijke volgende woord te voorspellen op basis van de vorige woorden in de zin. Prompt engineering is in te zetten voor verschillende nlp-taken zoals taalvertaling, samenvatten en het beantwoorden van vragen.
Kennisbank samenstellen
Het team van Van Kan heeft eerst een kennisbank gevuld met documenten die de nodige informatie bevatten om de chatbot te laten reageren op vragen van gebruikers. Daarvoor beschikt het over de softwaretool Pinecone, een vector-databasetool. In plaats van de documenten als tekst in deze opslagruimte te plaatsen, worden ze eerst omgezet in getallen – de vectoren. Meer precies wordt de tekst van elk document omgezet in embeddings. Dat zijn numerieke representaties van de semantische betekenis achter tekst. Twee teksten met gelijkaardige embeddings worden relatief dicht bij elkaar geplaatst en hebben dus een gelijkaardige betekenis. ‘Ter illustratie, embeddings van ‘man’ en ‘koning’ lijken meer op elkaar dan embeddings van ‘man’ en ‘schaken’. Tekstuele gegevens omzetten naar numerieke embeddings wordt gedaan door een machine-learningmodel dat gespecialiseerd is in het creëren van tekstuele embeddings. Het embeddingsmodel dat in dit project wordt gebruikt, is OpenAI’s text-embeddings-ada-002’, legt Van Kan uit.
Bij het bevragen van de kennisbank wordt vervolgens semantisch zoeken gebruikt. Daarbij wordt gekeken naar documenten die inhoud bevatten die het dichtst bij de zoekvraag komen op basis van semantische overeenkomst. Van Kan gaat ervan uit dat relevante documenten het antwoord op de gebruikersvraag bevatten. Pinecone voert het semantisch zoeken uit. De documenten worden dan gerangschikt van meest gelijkend naar minst gelijkend op de gebruikersvraag. Onthoud dat de embeddings betekenis vertegenwoordigen, dus het document met de hoogste similariteitsscore ten opzichte van de gebruikersquery bevat hoogstwaarschijnlijk semantische informatie met betrekking tot de gebruikersquery.
Inzet van taalmodel
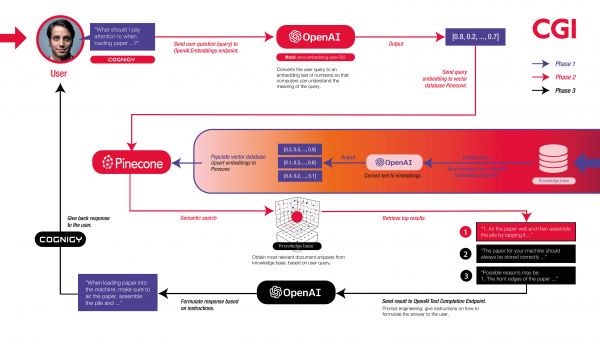
‘Als je eenmaal de relevante informatie hebt’, gaat Van Kan verder, ‘dan zetten we de kracht van llm in om tot een zinvol antwoord te komen. Wij hebben het taalmodel van OpenAI gebruikt.’ Om te voorkomen dat het taalmodel gaat hallucineren (antwoorden verzinnen bij gebrek aan data) heeft CGI de chatbot geleerd te melden dat er geen antwoord mogelijk is als er geen overeenkomende informatie wordt gevonden in de kennisbank.
‘Het antwoord is verzonden in een api-oproep naar OpenAI’s eindpunt voor voltooiingen (met behulp van het tekst-davinci-003-model). De chatinterface is gemaakt met Cognigy.AI. Door het taalmodel te gebruiken, is de taal van de documenten geen probleem; er is geen taalbarrière. Verder kun je het antwoord personaliseren, bijvoorbeeld door het zo te formuleren dat het overeenkomt met de leeftijdsgroep of achtergrondkennis van de gebruiker. Tot slot kan het antwoord een bepaalde bot persona of tone of voice volgen, die is af te stemmen op de richtlijnen van een bedrijf.’
Het koppelen van een llm aan een kennisbank is volgens Van Kan een krachtig hulpmiddel met veel potentiële toepassingsgebieden. Hij komt met meerdere voorbeelden. Te beginnen met het automatiseren van hr-gerelateerde vragen van werknemers. Een andere optie is om het te integreren in een customer relationship management-tool voor centra voor klantenondersteuning. Contactcentermedewerkers kunnen in realtime pop-ups ontvangen met het meest relevante kennisartikel dat betrekking heeft op het onderwerp van hun gesprek met een klant. Dit zou het werk van de klantenservice efficiënter en aangenamer maken en klanten nog betere ondersteuning bieden. ‘Of je zet de chatbot in om hiaten in een kennisbank te identificeren en op te vullen.’
Alleen als het nodig is
Van Kan benadrukt de tool alleen te gebruiken als er een goede kennisbank is, waarbij zowel de llm als semantisch zoeken haalbaar en gewenst zijn. Je moet nagaan of een toepassing echt het complexe taalbegrip en redenering vereist. Als een eenvoudige zoektaak volstaat, is een traditionelere aanpak aan te raden. ‘Bij het bouwen van een embeddingsvector-database is het belangrijk om zorgvuldig te beslissen wat een enkel document is. Bijvoorbeeld een pdf, hoofdstuk, pagina of enkele paragraaf? Weeg de noodzaak om voldoende informatie vast te leggen door grotere documenten te kiezen af tegen het risico van het introduceren van ruis en de moeilijkheid om specifieke details te vinden.’
Van Kan gaat in op kennisoverlap. Dit treedt op wanneer twee of meer documenten in de kennisbank vergelijkbare of tegenstrijdige informatie bevatten over hetzelfde onderwerp. Dit vormt een risico, omdat de opgehaalde documenten bepalen welke informatie wordt gebruikt om de uitvoer te construeren. Onnauwkeurige of verouderde gegevens zijn op te halen, wat leidt tot feitelijk onjuiste antwoorden. Dit benadrukt de noodzaak van onderhoud van de kennisbank door ervoor te zorgen dat deze accurate en actuele informatie bevat.
Ethische overwegingen

De architectuur van deze tool omvat meerdere instanties waarin gegevens naar softwaretools van derden worden verzonden. Het is cruciaal om de gevoeligheid van je gegevens en het privacybeleid van deze organisaties grondig te evalueren. Houd ook rekening met het gegevensopslagbeleid, aangezien de locatie van het datacenter waar deze tools hun gegevens opslaan kan variëren, samen met de bijbehorende wetten waaraan ze zich houden, bepleit Van Kan.
De ontwikkeling van interactieve technologieën moet altijd gebeuren in overeenstemming met ethische overwegingen zoals eerlijkheid, beperking van vooroordelen (bias; ras, sociaal-economisch, religie bijvoorbeeld) en gelijke behandeling van verschillende gebruikersgroepen. In de huidige context moet extra aandacht worden besteed aan uitlegbaarheid. Van Kan: ‘Je genereert tekst met een taalmodel. Dus je moet de uitkomst altijd controleren met jouw eigen expertise.’





